
Combining Multiprocessing and Asyncio in Python for Performance Boosts
Using a real-world example to demonstrate a map-reduce program


Introduction
Thanks to GIL, using multiple threads to perform CPU-bound tasks has never been an option. With the popularity of multicore CPUs, Python offers a multiprocessing solution to perform CPU-bound tasks. But until now, there were still some problems with using multiprocess-related APIs directly.
Before we start, we still have a small piece of code to aid in the demonstration:
import time
from multiprocessing import Process
def sum_to_num(final_num: int) -> int:
start = time.monotonic()
result = 0
for i in range(0, final_num+1, 1):
result += i
print(f"The method with {final_num} completed in {time.monotonic() - start:.2f} second(s).")
return resultThe method takes one argument and starts accumulating from 0 to this argument. Print the method execution time and return the result.
Problems with multiprocessing
def main():
# We initialize the two processes with two parameters, from largest to smallest
process_a = Process(target=sum_to_num, args=(200_000_000,))
process_b = Process(target=sum_to_num, args=(50_000_000,))
# And then let them start executing
process_a.start()
process_b.start()
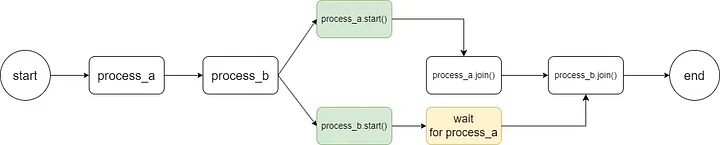
# Note that the join method is blocking and gets results sequentially
start_a = time.monotonic()
process_a.join()
print(f"Process_a completed in {time.monotonic() - start_a:.2f} seconds")
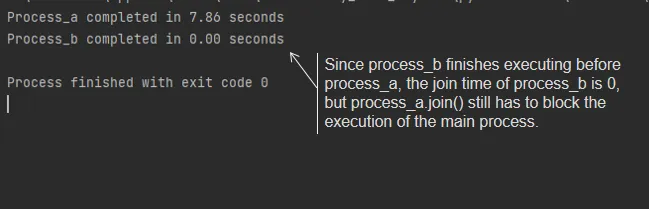
# Because when we wait process_a for join. The process_b has joined already.
# so the time counter is 0 seconds.
start_b = time.monotonic()
process_b.join()
print(f"Process_b completed in {time.monotonic() - start_b:.2f} seconds")As the code shows, we directly create and start multiple processes, and call the start and join methods of each process. However, there are some problems here:
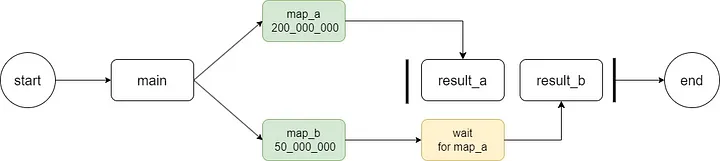
- The join method cannot return the result of task execution.
- the join method blocks the main process and executes it sequentially.
Even if the later tasks are executed faster than the earlier ones, as shown in the following figure:
Problems of using Pool
If we use multiprocessing.Pool, there are also some problems:
def main():
with Pool() as pool:
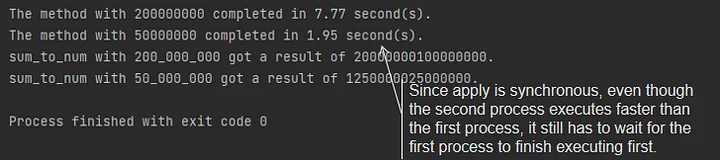
result_a = pool.apply(sum_to_num, args=(200_000_000,))
result_b = pool.apply(sum_to_num, args=(50_000_000,))
print(f"sum_to_num with 200_000_000 got a result of {result_a}.")
print(f"sum_to_num with 50_000_000 got a result of {result_b}.")As the code shows, Pool’s apply method is synchronous, which means you have to wait for the previously apply task to finish before the next apply task can start executing.
Of course, we can use the apply_async method to create the task asynchronously. But again, you need to use the get method to get the result blockingly. It brings us back to the problem with the join method:
def main():
with Pool() as pool:
result_a = pool.apply_async(sum_to_num, args=(200_000_000,))
result_b = pool.apply_async(sum_to_num, args=(50_000_000,))
print(f"sum_to_num with 200_000_000 got a result of {result_a.get()}.")
print(f"sum_to_num with 50_000_000 got a result of {result_b.get()}.")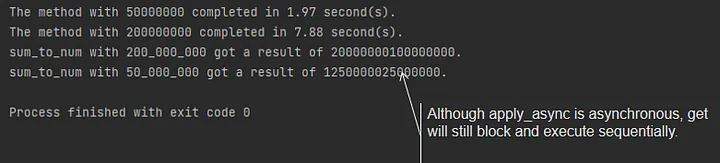
The problem with using ProcessPoolExecutor directly
So, what if we use concurrent.futures.ProcesssPoolExecutor to execute our CPU-bound tasks?
def main():
with ProcessPoolExecutor() as executor:
numbers = [200_000_000, 50_000_000]
for result in executor.map(sum_to_num, numbers):
print(f"sum_to_num got a result which is {result}.")As the code shows, everything looks great and is called just like asyncio.as_completed. But look at the results; they are still fetched in startup order. This is not at all the same as asyncio.as_completed, which gets the results in the order in which they were executed:
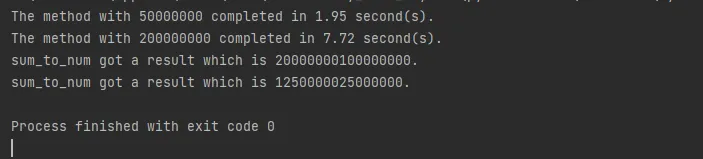
Use asyncio’s run_in_executor to fix it
Fortunately, we can use asyncio to handle IO-bound tasks, and its run_in_executor method to invoke multi-process tasks in the same way as asyncio. Not only unifying concurrent and parallel APIs but also solving the various problems we encountered above:
async def main():
loop = asyncio.get_running_loop()
tasks = []
with ProcessPoolExecutor() as executor:
for number in [200_000_000, 50_000_000]:
tasks.append(loop.run_in_executor(executor, sum_to_num, number))
# Or we can just use the method asyncio.gather(*tasks)
for done in asyncio.as_completed(tasks):
result = await done
print(f"sum_to_num got a result which is {result}")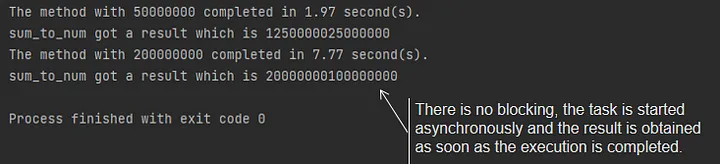
Since the sample code in the previous article was all about simulating what we should call the methods of the concurrent process, many readers still need help understanding how to use it in the actual coding after learning it. So after understanding why we need to perform CPU-bound parallel tasks in asyncio, today we will use a real-world example to explain how to use asyncio to handle IO-bound and CPU-bound tasks simultaneously and appreciate the efficiency of asyncio for our code.
Note: Before continuing, if you are interested in the practice of using asyncio.gather and asyncio.as_completed, you can read this article of mine:
 Peng Qian
Peng Qian
Real-world Case: Concurrent File Reading and Map-reduce Data Processing
In this case today, we will deal with two problems:
- How to read multiple datasets concurrently. Especially if the datasets are large or many. How to use asyncio to improve efficiency.
- How to use asyncio’s
run_in_executormethod to implement a MapReduce program and process datasets efficiently.
Before we start, I will explain to you how our code is going to be executed using a diagram:
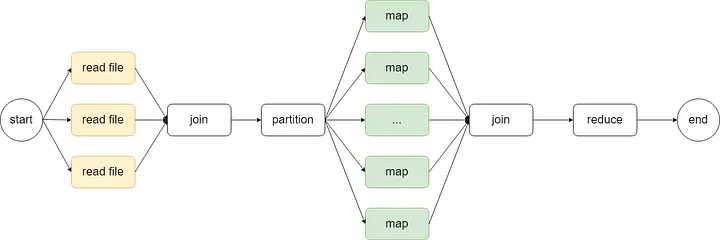
The yellow part represents our concurrent tasks. Since the CPU can process data from memory faster than IO can read data from disk, we first read all datasets into memory concurrently.
After the initial data merging and slicing, we come to the green part that represents the CPU parallel task. In this part, we will start several processes to map the data.
Finally, we get the intermediate results of all the processes in the main process and then use a reduce program to get the final results.
Of course, if you're looking for an out-of-the-box solution, Aiomultiprocess is what you need. Here's a detailed article about it:
Peng Qian
Data Preparation and Installation of Dependencies
Data preparation
In this case, we will use the Google Books Ngram Dataset, which counts the frequency of each string combination in various books by year from 1500 to 2012.
The Google Books Ngram dataset is free for any purpose, and today we will use these datasets below:
- http://storage.googleapis.com/books/ngrams/books/googlebooks-eng-all-1gram-20120701-a.gz
- http://storage.googleapis.com/books/ngrams/books/googlebooks-eng-all-1gram-20120701-b.gz
- http://storage.googleapis.com/books/ngrams/books/googlebooks-eng-all-1gram-20120701-c.gz
We aim to count the cumulative number of times each word is counted by the result set.
Dependency installation
To read the files concurrently, we will use the aiofiles library, which can support asyncio’s concurrent implementation.
If you are using pip, you can install it as follows:
$ pip install aiofilesIf you are using Anaconda, you can install it as follows:
$ conda install -c anaconda aiofilesCode Structure Design
Since this case is still relatively simple, for the sake of demonstration, we will use a .py script to do the whole thing here.
As an architect, before you start, you should plan your methods according to the flowchart design and try to follow the “single responsibility principle” for each method. Thus, do only one thing once upon each method:
import asyncio
from concurrent.futures import ProcessPoolExecutor
import functools
import time
from tqdm import tqdm
from tqdm.asyncio import tqdm_asyncio
from aiofiles import open
async def read_file(filename: str):
""" We will use the aiofiles API to read the files concurrently """
pass
async def get_all_file_content(file_names: list[str]):
""" Start concurrent tasks and join the file contents together """
pass
def partition(contents: list[str], partition_size: int):
""" Split the contents into multiple lists of partition_size length and return them as generator """
pass
def map_resource(chunk: list[str]) -> dict[str, int]:
""" The method that actually performs the map task
returns the sum of the counts corresponding to the keywords in the current partition.
"""
pass
def map_with_process(chunks: list[list[str]]):
""" Execute map tasks in parallel and join the results of multiple processes into lists """
pass
async def merge_resource(first: dict[str, int], second: dict[str, int]) -> dict[str, int]:
""" The actually reduce method sums the counts of two dicts with the same key """
pass
def reduce(intermediate_results: list[dict[str, int]]) -> dict[str, int]:
""" Use the functools.reduce method to combine all the items in the list """
pass
async def main(partition_size: int):
""" Entrance to all methods """
pass
if __name__ == "__main__":
asyncio.run(main(partition_size=60_000))Code Implementation
Next, we will implement each method step by step and finally integrate them to run together in the main method.
File reading
Method read_file will implement reading a single file with aiofiles:
async def read_file(filename: str):
""" We will use the aiofiles API to read the files concurrently """
async with open(filename, "r", encoding="utf-8") as f:
return await f.readlines()Method get_all_file_content will start the file reading task and, after all the files have been read, will merge each line of text into a list and return it.
async def get_all_file_content(file_names: list[str]):
""" Start concurrent tasks and join the file contents together """
print("Begin to read files...")
start = time.monotonic()
tasks, results = [], []
for filename in file_names:
tasks.append(asyncio.create_task(read_file(filename)))
temp_results = await asyncio.gather(*tasks)
results = [item for sublist in temp_results for item in sublist]
print(f"All files are read in {time.monotonic() - start:.2f} second(s)")
return resultsData grouping
Method partition will decompose the list into multiple smaller lists of partition_size length according to the passed partition_size and facilitate subsequent iterations using the generator:
def partition(contents: list[str], partition_size: int):
""" Split the contents into multiple lists of partition_size length and return them as generator """
for i in range(0, len(contents), partition_size):
yield contents[i: i+partition_size]Map processing data
Method map_resource is the actual map method. Use it to read each line of data from the list, use the word as the key and the sum of the frequencies as the value, and finally return a dict result.
def map_resource(chunk: list[str]) -> dict[str, int]:
""" The method that actually performs the map task
returns the sum of the counts corresponding to the keywords in the current partition.
"""
result = {}
for line in chunk:
word, _, count, _ = line.split('\t')
if word in result:
result[word] = result[word] + int(count)
else:
result[word] = int(count)
return resultIntegrating asyncio with multiprocessing
Method map_with_process calls asyncio’s run_in_executor method, which starts a pool of processes according to the number of CPU cores and executes the map method in parallel. And the final result is merged into a list by asyncio.gather method.
async def map_with_process(chunks: list[list[str]]):
""" Execute map tasks in parallel and join the results of multiple processes into lists """
print("Start parallel execution of map tasks...")
start = time.monotonic()
loop = asyncio.get_running_loop()
tasks = []
with ProcessPoolExecutor() as executor:
for chunk in chunks:
tasks.append(loop.run_in_executor(executor, map_resource, chunk))
print(f"All map tasks are executed in {time.monotonic()-start:.2f} second(s)")
return await asyncio.gather(*tasks)Reducing the merged data
Since the previous map process ends up with a list of word frequencies processed by multiple processes, we also need to use a reduce method to merge numerous dicts into a single final result, recording the final frequency of each word. Here we first write the method implementation of the reduce process.
def merge_resource(first: dict[str, int], second: dict[str, int]) -> dict[str, int]:
""" The actually reduce method sums the counts of two dicts with the same key """
merged = first
for key in second:
if key in merged:
merged[key] = merged[key] + second[key]
else:
merged[key] = second[key]
return mergedThen we call the functools.reduce method directly to merge the data.
def reduce(intermediate_results: list[dict[str, int]]) -> dict[str, int]:
""" Use the functools.reduce method to combine all the items in the list """
return functools.reduce(merge_resource, intermediate_results)Finally, implement the main method
Eventually, we integrate all the methods into the main method and call.
async def main(partition_size: int):
""" Entrance to all methods """
file_names = ["../data/googlebooks-eng-all-1gram-20120701-a",
"../data/googlebooks-eng-all-1gram-20120701-b",
"../data/googlebooks-eng-all-1gram-20120701-c"]
contents = await get_all_file_content(file_names)
chunks = partition(contents, partition_size)
intermediate_results = await map_with_process(chunks)
final_results = reduce(intermediate_results)
print(f'Aardvark has appeared {final_results["Aardvark"]} times.')Great! We get the sum of the frequencies of the word Aardvark in all the datasets. Task complete.
Using tqdm to indicate progress
In the previous article, we explained how to use tqdm to indicate the progress of asyncio tasks.
Peng Qian
Since in the real world, data processing of large datasets often takes a long time, during which we need to track the progress of code execution, we also need to add tqdm progress bars in the right places.
async def get_all_file_content(file_names: list[str]):
""" Start concurrent tasks and join the file contents together """
print("Begin to read files...")
start = time.monotonic()
tasks, results = [], []
for filename in file_names:
tasks.append(asyncio.create_task(read_file(filename)))
temp_results = await tqdm_asyncio.gather(*tasks) # add tqdm asyncio API
results = [item for sublist in temp_results for item in sublist]
print(f"All files are read in {time.monotonic() - start:.2f} second(s)")
return results
#########################################
async def map_with_process(chunks: list[list[str]]):
""" Execute map tasks in parallel and join the results of multiple processes into lists """
print("Start parallel execution of map tasks...")
start = time.monotonic()
loop = asyncio.get_running_loop()
tasks = []
with ProcessPoolExecutor() as executor:
for chunk in chunks:
tasks.append(loop.run_in_executor(executor, map_resource, chunk))
print(f"All map tasks are executed in {time.monotonic()-start:.2f} second(s)")
return await tqdm_asyncio.gather(*tasks) # add tqdm asyncio API
###########################################
def reduce(intermediate_results: list[dict[str, int]]) -> dict[str, int]:
""" Use the functools.reduce method to combine all the items in the list """
return functools.reduce(merge_resource, tqdm(intermediate_results))It looks much more professional now.

Conclusion
In today’s article, we explored some of the problems with multi-process code, such as the hassle of getting the results of each process and the inability to get the results in the order in which we execute the tasks.
We also explored the feasibility of integrating asyncio with ProcessPoolExecutor and the advantages that such integration brings to us. For example, it unifies the API for concurrent and parallel programming, simplifies our programming process, and allows us to obtain execution results in order of completion.
Finally, we explain how we can alternate between concurrent and parallel programming techniques to help us execute our code efficiently in data science tasks through a real-world case study that exists.
Due to the limited ability of individuals, there are inevitably few places in the case, so I welcome your comments and corrections so that we can learn and progress together.



