
Implementing the train_step Method in Keras 3: From Errors to Solutions
Official code example hasn't kept up with framework updates


Keras has been updated to version 3.0, but many code examples on the official website have not been maintained in time. So, when you use Pytorch as the backend framework, these code examples will likely fail.
For instance, take the example related to the VAE model, and another concerning the GAN model.
Both examples share a common feature: they rewrite the train_step method of keras.Model to implement a custom model training and gradient update process. However, following these examples will likely result in errors.
After several failed attempts, I finally figured out how to write the train_step method correctly. Today, I will share my solution with you, hoping to help you solve similar problems.
If you are unfamiliar with the new changes in Keras 3, you can read my deep dive article here:
Introducing Some Background Knowledge
Before we start, I need to provide you with some background knowledge about the Keras training loop, as shown in the diagram below.
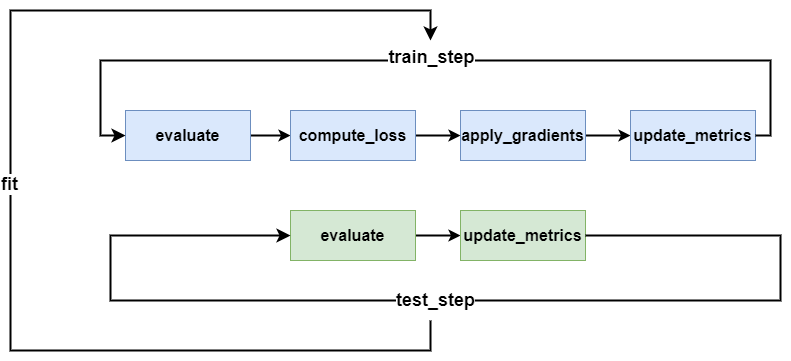
In the fit method of keras.Model, you will set two parameters: epochs and batch_size.
Epochs set how many times we train the model with the entire data.
For one training loop, we use batch_size to divide the data into multiple batches. Each batch is a step, and the model only starts gradient updates after a step is trained.
For each step, Keras divides it into train_step and test_step methods. The train_step method is executed only during training, while the test_step method is performed during validation.
The train_step method, includes four processes: forward propagation, loss calculation, gradient update, and updating metrics. So when we need to customize the model training process, we can implement it in the train_step method.
Getting to the Point
Starting with a base model
I don't like to start by throwing a whole project's code at you, as it can be overwhelming and unclear where the focus should be. So let's keep it simple, starting with a basic model based on the functional API.
(X_train, y_train), (X_test, y_test) = keras.datasets.mnist.load_data()
X_train = X_train.astype('float32') / 255.
X_test = X_test.astype('float32') / 255.
def get_base_model() -> keras.models.Model:
inputs = layers.Input(shape=(28, 28, 1))
x = layers.Flatten()(inputs)
x = layers.Dense(128, activation='relu')(x)
x = layers.Dense(64, activation='relu')(x)
x = layers.Dropout(0.25)(x)
outputs = layers.Dense(10, activation='softmax')(x)
return keras.models.Model(inputs=inputs, outputs=outputs)
base_model = get_base_model()
base_model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
base_model.fit(X_train, y_train, epochs=5, batch_size=512,
validation_data=(X_test, y_test))
This model is a very simple task of classifying the MNIST dataset. So the training process is also straightforward: set the optimizer, loss, and metrics in the compile method, and you can start training.
Let's see how the functional API works
First, let's add some custom processes, assuming we do not use the loss set in the compile method, but instead want to customize the loss calculation and gradient update methods. We need to use the subclassing API to implement a Model subclass and then rewrite the train_step method.
class CustomModel(keras.Model):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.loss_fn = keras.losses.SparseCategoricalCrossentropy()
self.total_loss_tracker = keras.metrics.Mean(name='total_loss')
@property
def metrics(self):
return [
self.total_loss_tracker
]
def train_step(self, data):
X, y = data
self.zero_grad()
y_pred = self(X, training=True)
total_loss = self.loss_fn(y, y_pred)
total_loss.backward()
trainable_variables = self.trainable_variables
gradients = [v.value.grad for v in trainable_variables]
with torch.no_grad():
self.optimizer.apply(gradients, trainable_variables)
self.total_loss_tracker.update_state(total_loss)
return {
'custom_loss' : self.total_loss_tracker.result()
}We focus on demonstrating the steps of train_step, so inside the sub-Model, I still use SparseCategoricalCrossentropy to calculate the loss.
At the same time, we need to replace the Model class used by the functional API.
def get_custom_model():
inputs = layers.Input(shape=(28, 28, 1))
x = layers.Flatten()(inputs)
x = layers.Dense(128, activation='relu')(x)
x = layers.Dense(64, activation='relu')(x)
x = layers.Dropout(0.25)(x)
outputs = layers.Dense(10, activation='softmax')(x)
return CustomModel(inputs=inputs, outputs=outputs)Since we are using Pytorch as the backend framework, I will also show you what the gradient update process based on Pytorch looks like.
As shown in the code, we need to pay attention to the following lines of code:
- When using Pytorch as the backend, the loss calculation process no longer needs to be placed in the
tf.GradientTape()context. - Before each batch starts, we need to use
self.zero_grad()to reset the gradients. - After the loss calculation is completed,
loss.backward()will perform the backward propagation process. - We need to perform gradient updates in the
torch.no_grad()context to avoid repeated gradient calculations.
If we compare our code with the official website's example, we've done quite well. Next, let's remove the loss and metrics parameters from the compile method (since we have already manually calculated them in the sub-Model), and then try training the model.
custom_model = get_custom_model()
custom_model.compile(optimizer='adam')
custom_model.fit(X_train, y_train, epochs=5, batch_size=512,
validation_data=(X_test, y_test))Boom, the training went wrong, facing our first error today.
ValueError: No loss to compute. Provide a `loss` argument in `compile()`.The error message is hard to understand: We have already calculated the loss in the train_step method, so why do we still need to provide the loss parameter in the compile method? Where is this loss method used?
Recalling the model training process diagram mentioned earlier, I noted that when the fit method includes validation_data parameter, we need to rewrite the test_step method to indicate the calculation process of the validation data.
So we need to rewrite another test_step method in the sub-Model, which is quite simple, just writing out the forward propagation calculation process.
def test_step(self, data):
X, y = data
y_pred = self.model(X, training=False)
for metric in self.metrics:
metric.update_state(y, y_pred)
return {m.name: m.result() for m in self.metrics}Of course, for models like GANs, where the forward propagation itself is quite complex, it's not easy to implement in the test_step. We can also directly remove the validation_data or validation_split parameters from the fit method.
How will it work with the subclassing API
We talked about the scenario of the functional API earlier. Now let's talk about what problems might arise when rewriting the train_step under the subclassing API, and how to solve them.
Typically, when our training process is too complex to be implemented with the functional API, we recommend using the subclassing API. We can take the AutoEncoder architecture as an example.
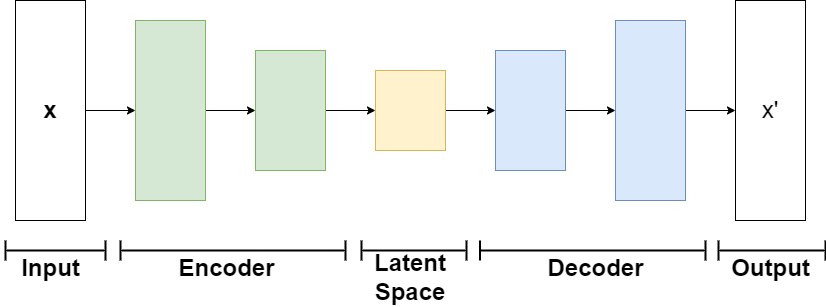
Suppose we rewrite the code for MNIST classification into an Encoder.
class Encoder(keras.Model):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.flatten = layers.Flatten()
self.fc1 = layers.Dense(128, activation='relu')
self.fc2 = layers.Dense(64, activation='relu')
self.dropout = layers.Dropout(0.25)
self.out = layers.Dense(10, activation='softmax')
def call(self, data):
x = self.flatten(data)
x = self.fc1(x)
x = self.fc2(x)
x = self.dropout(x)
out = self.out(x)
return outThen we put it into an AutoEncoder, ready to customize the training process. To simplify the code, we skip the implementation and training process of the Decoder. The implementation of the train_step method is consistent with the previous CustomModel.
Next, let's see what happens if we train the AutoEncoder.
RuntimeError: Unable to automatically build the model. Please build it yourself before calling fit/evaluate/predict. A model is 'built' when its variables have been created and its `self.built` attribute is True. Usually, calling the model on a batch of data is the right way to build it.
Exception encountered:
'Exception encountered when calling AutoEncoder.call().
Model AutoEncoder does not have a `call()` method implemented.
Arguments received by AutoEncoder.call():
• args=('torch.Tensor(shape=torch.Size([512, 28, 28]), dtype=float32)',)
• kwargs=<class 'inspect._empty'>'Another error!
The error text is a bit long, but the key point is in the middle:
Model AutoEncoder does not have a `call()` method implemented.Wait, what? If you look at the official website's several examples about the train_step: Example 1, Example 2, Example 3, Example 4. They didn't mention that when rewriting the train_step loop, you need to implement the call method.
And for models like VAE or GAN, where the training process is quite complex, there isn't a need to implement the call method.
So why are we still prompted to implement the call method here?
After checking the Keras source code and comparing the differences between TensorFlow and Pytorch, I have a hypothesis: This may be related to Keras's computation graph.
We all know that when using Keras's Sequential and functional API to build models, a static computation graph is generated, but not in the case of using the subclassing API.
Therefore, for a subclassing API Model, it needs to use call to determine the computational architecture between the layers in the model. So when we rewrite the train_step using the subclassing method, it prompts the "does not have a call() method implemented." error.
Based on this hypothesis, let's add a call method to the AutoEncoder and try again.
def call(self, data):
x = self.encoder(data)
return xBingo, the model training starts normally.
Epoch 1/5
118/118 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - total_loss: 1.0065
Epoch 2/5
118/118 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - total_loss: 0.2299
Epoch 3/5
118/118 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - total_loss: 0.1600
Epoch 4/5
118/118 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - total_loss: 0.1270
Epoch 5/5
118/118 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step - total_loss: 0.1013Similarly, when you learn from the official website's examples of VAE and GAN and encounter code errors, you can also solve them by adding a call method.
Conclusion
Due to the scarcity of related materials, when we learn about Keras 3, we mainly rely on the official website's examples.
However, these examples seem not to have kept up with the framework updates, causing some code to report errors when executed with Pytorch as the backend.
This article focuses on the feature of implementing a custom training process by rewriting the train_step method, explaining the possible errors and solutions.
Of course, if a simpler solution is available to train the model, it is not recommended to implement the training process yourself, as debugging deep learning is quite troublesome and often encounters various problems.
If you want to learn more about Keras 3, feel free to leave me a message, and I will do my best to answer.



