
Mastering Synchronization Primitives in Python Asyncio: A Comprehensive Guide
Best practices for asyncio.Lock, asyncio.Semaphore, asyncio.Event and asyncio.Condition


In this article, I will introduce why you need synchronization primitives in Python’s asyncio and best practices for several synchronization primitives.
And in the last part of the article, I will walk you through an example of synchronization primitives in action.
Introduction
Why do you need synchronization primitives in asyncio
Anyone who has used Python multithreading knows that multiple threads share the same memory block.
So when multiple threads perform non-atomic operations on the same area simultaneously, a thread-safe problem occurs.
Since asyncio runs on a single thread, does it not have similar thread-safe issues? The answer is no.
Concurrent tasks in asyncio are executed asynchronously, which means that there may be alternating execution of multiple tasks in time.
A concurrency bug is triggered when one task accesses a particular memory area and waits for an IO operation to return, another task is also accessing this memory simultaneously.
To avoid such bugs, Python asyncio introduces a synchronization primitive feature similar to multithreading.
Also, to avoid too many tasks accessing a resource concurrently, asyncio’s synchronization primitives provide the ability to protect the resource by limiting the number of tasks accessing it simultaneously.
Next, let’s take a look at what synchronization primitives are available in asyncio.
Python Asyncio’s Synchronization Primitives
Lock
Before we introduce this API, let’s look at a situation:
Suppose we have a concurrent task that needs a copy of the website data. It will first check if it’s in the cache; if it is, it will fetch it from the cache, and if not, it will read it from the website.
Since it takes some time to read the website data to return and update the cache, when multiple concurrent tasks are executed at the same time, they all assume that this data does not exist in the cache and launch remote requests at the same time, as shown in the following code:
import asyncio
import aiohttp
cache = dict()
async def request_remote():
print("Will request the website to get status.")
async with aiohttp.ClientSession() as session:
response = await session.get("https://www.example.com")
return response.status
async def get_value(key: str):
if key not in cache:
print(f"The value of key {key} is not in cache.")
value = await request_remote()
cache[key] = value
else:
print(f"The value of key {key} is already in cache.")
value = cache[key]
print(f"The value of {key} is {value}")
return value
async def main():
task_one = asyncio.create_task(get_value("status"))
task_two = asyncio.create_task(get_value("status"))
await asyncio.gather(task_one, task_two)
if __name__ == "__main__":
asyncio.run(main())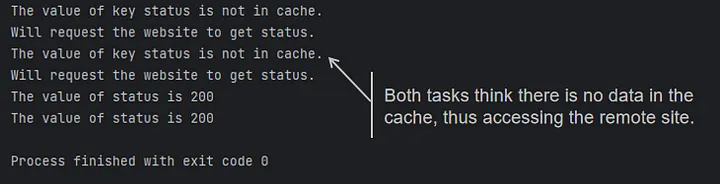
Which is not in line with our original design intent, so asyncio.Lock comes in handy.
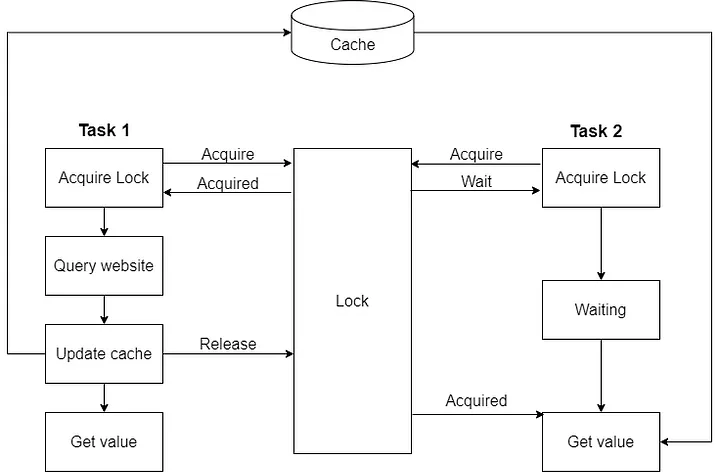
We can check if there is data in the cache when concurrent tasks need to get a lock first, and other tasks that do not get a lock will wait.
Until the task that gets the lock finishes updating the cache and releases the lock, the other tasks can continue to execute.
The entire flowchart is shown below:
Let’s see how to write the code:
import asyncio
from asyncio import Lock
import aiohttp
cache = dict()
lock = Lock()
async def request_remote():
# ...
async def get_value(key: str):
async with lock:
if key not in cache:
print(f"The value of key {key} is not in cache.")
value = await request_remote()
cache[key] = value
else:
print(f"The value of key {key} is already in cache.")
value = cache[key]
print(f"The value of {key} is {value}")
return value
async def main():
# ...
if __name__ == "__main__":
asyncio.run(main())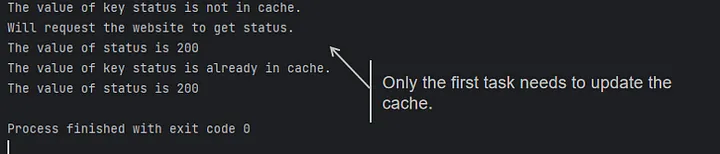
Problem solved, isn’t it simple?
Semaphore
Sometimes, we need to access a resource with limited concurrent requests.
For example, a particular database only allows five connections to be opened simultaneously. Or depending on the type of subscription you have, a web API only supports a certain number of concurrent requests at the same time.
In this case, you need to use asyncio.Semaphore. asyncio.Semaphore uses an internal counter that decrements by one each time a Semaphore lock is acquired until it reaches zero.
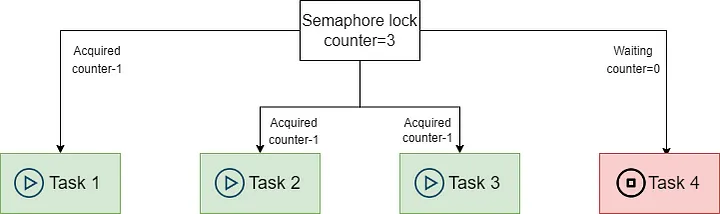
When the counter of asyncio.Semaphore is zero, other tasks that need the lock will wait.
When calling the release method after the execution of other tasks, the counter will be increased by one. The waiting tasks can continue to execute.
The code example is as follows:
import asyncio
from asyncio import Semaphore
from aiohttp import ClientSession
async def get_url(url: str, session: ClientSession, semaphore: Semaphore):
print('Waiting to acquire semaphore...')
async with semaphore:
print('Semaphore acquired, requesting...')
response = await session.get(url)
print('Finishing requesting')
return response.status
async def main():
# Although we start 1000 tasks, only 10 tasks will be executed at the same time.
semaphore: Semaphore = Semaphore(10)
async with ClientSession() as session:
tasks = [asyncio.create_task(get_url("https://www.example.com", session, semaphore))
for _ in range(1000)]
await asyncio.gather(*tasks)
if __name__ == "__main__":
asyncio.run(main())In this way, we can limit the number of connections that can be accessed concurrently.
BoundedSemaphore
Sometimes, due to code limitations, we can’t use async with to manage the acquire and release of semaphore locks, so we might call acquire somewhere and release somewhere else.
What happens if we accidentally call the asyncio.Semaphorerelease method multiple times?
import asyncio
from asyncio import Semaphore
async def acquire(semaphore: Semaphore):
print("acquire: Waiting to acquire...")
async with semaphore:
print("acquire: Acquired...")
await asyncio.sleep(5)
print("acquire: Release...")
async def release(semaphore: Semaphore):
print("release: Releasing as one off...")
semaphore.release()
print("release: Released as one off...")
async def main():
semaphore = Semaphore(2)
await asyncio.gather(asyncio.create_task(acquire(semaphore)),
asyncio.create_task(acquire(semaphore)),
asyncio.create_task(release(semaphore)))
await asyncio.gather(asyncio.create_task(acquire(semaphore)),
asyncio.create_task(acquire(semaphore)),
asyncio.create_task(acquire(semaphore)))
if __name__ == "__main__":
asyncio.run(main())As the code shows, we are limited to running two tasks simultaneously, but because we called release more than once, we can run three tasks at the same time next time.
To solve this problem, we can use asyncio.BoundedSemaphore .
As we know from the source code, when calling the release, a ValueError is thrown if the counter value is greater than the value set during initialization:
import asyncio
from asyncio import BoundedSemaphore
async def main():
semaphore = BoundedSemaphore(2)
await semaphore.acquire()
semaphore.release()
semaphore.release()
if __name__ == "__main__":
asyncio.run(main())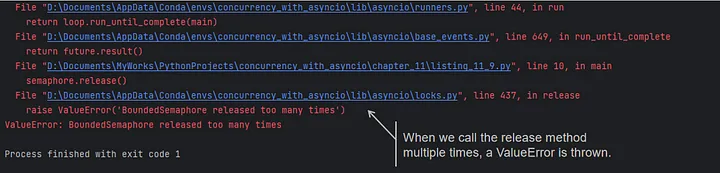
Therefore, the problem is being solved.
Event
Event maintains an internal boolean variable as a flag. asyncio.Event has three common methods: wait, set, and clear.
When the task runs to event.wait(), the task is in wait. At this point, you can call event.set() to set the internal marker to True, and all the waiting tasks can continue to execute.
When the task is finished, you need to call event.clear() method to reset the value of the marker to False, to restore the event to its initial state, and you can continue to use the event next time.
Instead of the sample code, I will show you how to use Event to implement an event bus at the end of the article.
Condition
asyncio.Condition is similar to asyncio.Lock and asyncio.Event combined.
First, we will use async with to ensure that the condition lock is acquired, and then we call condition.wait() to release the condition lock and make the task wait temporarily.
When condition.wait() passes, we regain the condition lock to ensure that only one task executes simultaneously.
While a task temporarily releases the lock and goes into wait by condition.wait(), another task can either async with to the condition lock and notify all waiting tasks to continue execution by the condition.notify_all() method.
The flowchart is shown below:
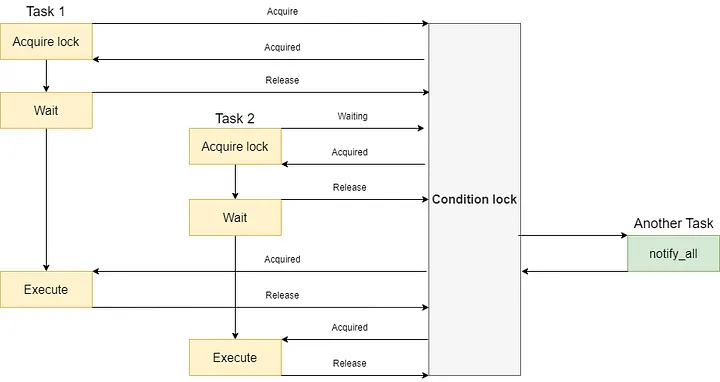
We can demonstrate the effect of asyncio.Condition with a piece of code:
import asyncio
from asyncio import Condition
async def do_work(condition: Condition):
print("do_work: Acquiring condition lock...")
async with condition:
print("do_work: Acquired lock, release and waiting for notify...")
await condition.wait()
print("do_work: Condition notified, re-acquire and do work.")
await asyncio.sleep(1)
print("do_work: Finished work, release condition lock.")
async def fire_event(condition: Condition):
await asyncio.sleep(5)
print("fire_event: Acquiring condition lock....")
async with condition:
print("fire_event: Acquired lock, notify all workers.")
condition.notify_all()
print("fire_event: Notify finished, release the work...")
async def main():
condition = Condition()
asyncio.create_task(fire_event(condition))
await asyncio.gather(do_work(condition), do_work(condition))
if __name__ == "__main__":
asyncio.run(main())Sometimes, we need asyncio.Condition to wait for a specific event to occur before proceeding to the next step. We can call the condition.wait_for() method and pass a method as an argument.
Each time condition.notify_all is called, condition.wait_for checks the result of the execution of the parameter method and ends the wait if it is True, or continues to wait if it is False.
We can demonstrate the effect of wait_for with an example. In the following code, we will simulate a database connection.
Before executing the SQL statement, the code will check if the database connection is initialized and execute the query if the connection initialization is completed, or wait until the connection is completed initializing:
import asyncio
from asyncio import Condition
from enum import Enum
class ConnectionState(Enum):
WAIT_INIT = 0
INITIALING = 1
INITIALIZED = 2
class Connection:
def __init__(self):
self._state = ConnectionState.WAIT_INIT
self._condition = Condition()
async def initialize(self):
print("initialize: Preparing initialize the connection.")
await self._change_state(ConnectionState.INITIALING)
await asyncio.sleep(5)
print("initialize: Connection initialized")
await self._change_state(ConnectionState.INITIALIZED)
async def execute(self, query: str):
async with self._condition:
print("execute: Waiting for connection initialized")
await self._condition.wait_for(self._is_initialized)
print(f"execute: Connection initialized, executing query: {query}")
await asyncio.sleep(5)
print("execute: Execute finished.")
async def _change_state(self, state: ConnectionState):
print(f"_change_state: Will change state from {self._state} to {state}")
self._state = state
print("_change_state: Change the state and notify all..")
async with self._condition:
self._condition.notify_all()
def _is_initialized(self):
if self._state is not ConnectionState.INITIALIZED:
print("_is_initialized: The connection is not initialized.")
return False
print("_is_initialized: The connection is ready.")
return True
async def main():
connection = Connection()
task_one = asyncio.create_task(connection.execute("SELECT * FROM table"))
task_two = asyncio.create_task(connection.execute("SELECT * FROM other_table"))
asyncio.create_task(connection.initialize())
await asyncio.gather(task_one, task_two)
if __name__ == "__main__":
asyncio.run(main())Some Tips for Using Synchronization Primitives
Remember to use timeout or cancelation when needed
When using synchronization primitives, we are generally waiting for the completion of a specific IO operation.
However, due to network fluctuations or other unknown reasons, the IO operation of a task may take longer than others.



