
Supercharge Your Python Asyncio With Aiomultiprocess: A Comprehensive Guide
Harness the power of asyncio and multiprocessing to turbocharge your applications


In this article, I will take you into the world of aiomultiprocess, a library that combines the powerful capabilities of Python asyncio and multiprocessing.
This article will explain through rich code examples and best practices.
By the end of this article, you will understand how to leverage the powerful features of aiomultiprocess to enhance your Python applications, just like a head chef leading a team of chefs to create a delicious feast.
Introduction
Imagine that you want to invite your colleagues over for a big meal on the weekend. How would you do it?
As an experienced chef, you certainly wouldn’t cook one dish at a time; that would be too slow. You would efficiently use your time, letting multiple tasks happen simultaneously.
For example, while you wait for the water to boil, you can step away to wash vegetables. This way, you can throw the vegetables into the pot when the water is boiling. This is the charm of concurrency.
However, recipes can often be cruel: you need to keep stirring when making soup; vegetables need to be washed and chopped; you also need to bake bread, fry steaks, and more.
When there are many dishes to prepare, you’ll be overwhelmed.
Fortunately, your colleagues won’t just sit around waiting to eat. They will come into the kitchen to help you, with each additional person acting like an additional working process. This is the powerful combination of multiprocessing and concurrency.
The same is true for code. Even with asyncio, has your Python application still encountered bottlenecks? Are you looking for ways to further improve the performance of your concurrent code? If so, aiomultiprocess is the answer you’ve been looking for.
How to Install and Basic Usage
Installation
If you use pip, install it like this:
python -m pip install aiomultiprocessIf you use Anaconda, install it from conda-forge:
conda install -c conda-forge aiomultiprocessBasic usage
aiomultiprocess consists of three main classes:
Process is the base class for the other two classes and is used to start a process and execute a coroutine function. You won’t usually need to use this class.
Worker is used to start a process, execute a coroutine function, and return the result. We also won’t be using this class.
Pool is the core class we will focus on. Like multiprocessing.Pool, it starts a process pool, but its context needs to be managed using async with. We will use the two methods of Pool: map and apply.
The map method accepts a coroutine function and an iterable. The Pool will iterate over the iterable and assign the coroutine function to run on various processes. The result of the map method can be asynchronously iterated using async for:
import asyncio
import random
import aiomultiprocess
async def coro_func(value: int) -> int:
await asyncio.sleep(random.randint(1, 3))
return value * 2
async def main():
results = []
async with aiomultiprocess.Pool() as pool:
async for result in pool.map(coro_func, [1, 2, 3]):
results.append(result)
print(results)
if __name__ == "__main__":
asyncio.run(main())The apply method accepts a coroutine function and the required argument tuple for the function. According to the scheduler’s rules, the Pool will assign the coroutine function to an appropriate process for execution.
import asyncio
import random
import aiomultiprocess
async def coro_func(value: int) -> int:
await asyncio.sleep(random.randint(1, 3))
return value * 2
async def main():
tasks = []
async with aiomultiprocess.Pool() as pool:
tasks.append(pool.apply(coro_func, (1,)))
tasks.append(pool.apply(coro_func, (2,)))
tasks.append(pool.apply(coro_func, (3,)))
results = await asyncio.gather(*tasks)
print(results) # Output: [2, 4, 6]
if __name__ == "__main__":
asyncio.run(main())Implementation Principle and Practical Examples
Implementation principle of aiomultiprocess.Pool
In a previous article, I explained how to distribute asyncio tasks across multiple CPU cores.
The general approach is to start a process pool in the main process using loop.run_in_executor. Then, an asyncio event loop is created in each process in the process pool, and the coroutine functions are executed in their respective loops. The schematic is as follows:
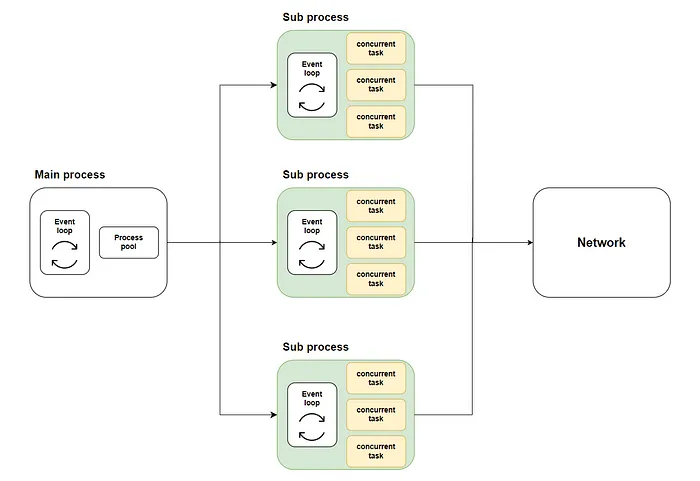
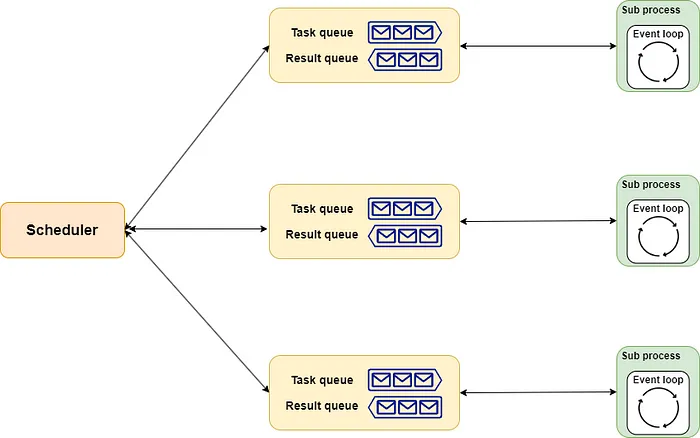
The implementation of aiomultiprocess.Pool is similar. It includes scheduler, queue, and process as its three components.
- The
schedulercan be understood as the head chef, responsible for allocating tasks in a suitable way to each chef. Of course, you can hire (implement) a head chef suitable for your needs. - The
queueis like the kitchen’s assembly line. Strictly speaking, it includes an order line and a delivery line. The head chef passes the menu through the order line to the chefs, and the chefs return the completed dishes through the delivery line. - The
processis like the chefs in the restaurant. They each handle several dishes concurrently according to the allocation. Each time a dish is ready, it will be handed over in the allocated order.
The entire schematic is shown below:
Real-world Example
Based on the introduction provided earlier, you should now understand how to use aiomultiprocess. Let’s dive into a real-world example to experience the power of it.
Or, you can find a free version here:
 Peng Qian
Peng Qian
First, we’ll use a remote call and a loop calculation to simulate the process of data retrieval and processing in real life. This method demonstrates that IO-bound and CPU-bound tasks are often mixed together, and the boundary between them is not so clear-cut.
import asyncio
import random
import time
from aiohttp import ClientSession
from aiomultiprocess import Pool
def cpu_bound(n: int) -> int:
result = 0
for i in range(n*100_000):
result += 1
return result
async def invoke_remote(url: str) -> int:
await asyncio.sleep(random.uniform(0.2, 0.7))
async with ClientSession() as session:
async with session.get(url) as response:
status = response.status
result = cpu_bound(status)
return resultNext, let’s use the traditional asyncio approach to call this task 30 times as a baseline:
async def main():
start = time.monotonic()
tasks = [asyncio.create_task(invoke_remote("https://www.example.com"))
for _ in range(30)]
await asyncio.gather(*tasks)
print(f"All jobs done in {time.monotonic() - start} seconds")
if __name__ == "__main__":
asyncio.run(main())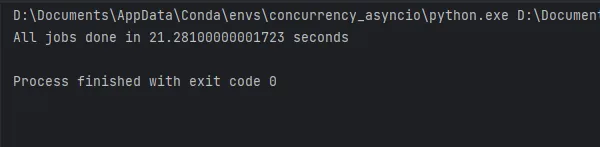
The code execution results are shown in the figure, and it takes approximately 21 seconds. Now let’s see how much aiomultiprocess can improve this.
Using aiomultiprocess is simple. The original concurrent code does not need to be modified. You only need to adjust the code in the main method to run inside the Pool:
async def main():
start = time.monotonic()
async with Pool() as pool:
tasks = [pool.apply(invoke_remote, ("https://www.example.com",))
for _ in range(30)]
await asyncio.gather(*tasks)
print(f"All jobs done in {time.monotonic() - start} seconds")
if __name__ == "__main__":
asyncio.run(main())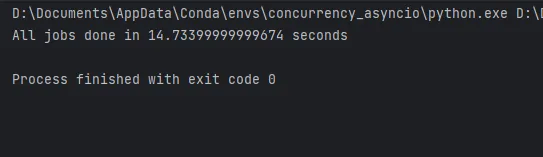
As you can see, the code using aiomultiprocess takes only 14 seconds to complete on my laptop. The performance improvement would be even greater on a more powerful computer.
Detailed Best Practices
Finally, based on my experience, let me share some more practical best practices.
Use pool only
Although aiomultiprocess also provides the Process and Worker classes for us to choose from, we should always use the Pool class to ensure maximum efficiency due to the significant resource consumption of creating processes.
How to use queues
In a previous article, I explained how to use asyncio.Queue to implement the producer-consumer pattern to balance resources and performance.
In aiomultiprocess, we can also use queues. However, since we are in a process pool, we cannot use asyncio.Queue. At the same time, we cannot directly use multiprocessing.Queue in the process pool.
In this case, you should use multiprocessing.Manager().Queue() to create a queue, with the code as follows:
import random
import asyncio
from multiprocessing import Manager
from multiprocessing.queues import Queue
from aiomultiprocess import Pool
async def worker(name: str, queue: Queue):
while True:
item = queue.get()
if not item:
print(f"worker: {name} got the end signal, and will stop running.")
queue.put(item)
break
await asyncio.sleep(random.uniform(0.2, 0.7))
print(f"worker: {name} begin to process value {item}", flush=True)
async def producer(queue: Queue):
for i in range(20):
await asyncio.sleep(random.uniform(0.2, 0.7))
queue.put(random.randint(1, 3))
queue.put(None)
async def main():
queue: Queue = Manager().Queue()
producer_task = asyncio.create_task(producer(queue))
async with Pool() as pool:
c_tasks = [pool.apply(worker, args=(f"worker-{i}", queue))
for i in range(5)]
await asyncio.gather(*c_tasks)
await producer_task
if __name__ == "__main__":
asyncio.run(main())Using initializer to initialize resources
Suppose you need to use an aiohttp session or a database connection pool in a coroutine method, but we cannot pass arguments when creating tasks in the main process because these objects cannot be pickled.
An alternative is to define a global object and an initialization method. In this initialization method, access the global object and perform initialization.
Just like multiprocessing.Pool, aiomultiprocess.Pool can accept an initialization method and corresponding initialization parameters when initialized. This method will be called to complete the initialization when each process starts:
import asyncio
from aiomultiprocess import Pool
import aiohttp
from aiohttp import ClientSession, ClientTimeout
session: ClientSession | None = None
def init_session(timeout: ClientTimeout = None):
global session
session = aiohttp.ClientSession(timeout=timeout)
async def get_status(url: str) -> int:
global session
async with session.get(url) as response:
status_code = response.status
return status_code
async def main():
url = "https://httpbin.org/get"
timeout = ClientTimeout(2)
async with Pool(initializer=init_session, initargs=(timeout,)) as pool:
tasks = [asyncio.create_task(pool.apply(get_status, (url,)))
for i in range(3)]
status = await asyncio.gather(*tasks)
print(status)
if __name__ == "__main__":
asyncio.run(main())Exception handling and retries
Although aiomultiprocess.Pool provides the exception_handler parameter to help with exception handling, if you need more flexibility, you need to combine it with asyncio.wait. For the usage of asyncio.wait, you can refer to my previous article.
With asyncio.wait, you can get tasks that encounter exceptions. After extracting the task, you can make some adjustments and then re-execute the task, as shown in the code below:
import asyncio
import random
from aiomultiprocess import Pool
async def worker():
await asyncio.sleep(0.2)
result = random.random()
if result > 0.5:
print("will raise an exception")
raise Exception("something error")
return result
async def main():
pending, results = set(), []
async with Pool() as pool:
for i in range(7):
pending.add(asyncio.create_task(pool.apply(worker)))
while len(pending) > 0:
done, pending = await asyncio.wait(pending, return_when=asyncio.FIRST_EXCEPTION)
print(f"now the count of done, pending is {len(done)}, {len(pending)}")
for result in done:
if result.exception():
pending.add(asyncio.create_task(pool.apply(worker)))
else:
results.append(await result)
print(results)
if __name__ == "__main__":
asyncio.run(main())Using Tenacity for retries
Of course, we have more flexible and powerful options for exception handling and retries, such as using the Tenacity library, which I explained in this article.
With Tenacity, the code above can be significantly simplified. You just need to add a decorator to the coroutine method, and the method will automatically retry when an exception is thrown.
import asyncio
from random import random
from aiomultiprocess import Pool
from tenacity import *
@retry()
async def worker(name: str):
await asyncio.sleep(0.3)
result = random()
if result > 0.6:
print(f"{name} will raise an exception")
raise Exception("something wrong")
return result
async def main():
async with Pool() as pool:
tasks = pool.map(worker, [f"worker-{i}" for i in range(5)])
results = await tasks
print(results)
if __name__ == "__main__":
asyncio.run(main())Using tqdm to indicate progress
I like tqdm because it can always tell me how far the code has run when I’m waiting in front of the screen. This article also explains how to use it.
Since aiomultiprocess uses asyncio’s API to wait for tasks to complete, it is also compatible with tqdm:
import asyncio
from random import uniform
from aiomultiprocess import Pool
from tqdm.asyncio import tqdm_asyncio
async def worker():
delay = uniform(0.5, 5)
await asyncio.sleep(delay)
return delay * 10
async def main():
async with Pool() as pool:
tasks = [asyncio.create_task(pool.apply(worker)) for _ in range(1000)]
results = await tqdm_asyncio.gather(*tasks)
print(results[:10])
if __name__ == "__main__":
asyncio.run(main())Conclusion
Running asyncio code is like a chef cooking a meal. Even if you can improve efficiency by running different tasks concurrently, you’ll eventually encounter bottlenecks.
The simplest solution at this point is to add more chefs to increase the parallelism of the cooking process.
Aiomultiprocess is such a powerful Python library. By allowing concurrent tasks to run on multiple processes, it perfectly breaks through the performance bottlenecks caused by asyncio’s single-threaded nature.
The use and best practices of aiomultiprocess in this article are based on my work experience. If you’re interested in any aspect, feel free to comment and join the discussion.



