
Use These Methods to Make Your Python Concurrent Tasks Perform Better
Best practices for asyncio.gather, asyncio.as_completed, and asyncio.wait


Where the Problem Lies
It has always been the case that Python’s multi-threaded performance has never lived up to expectations because of GIL.
So since version 3.4, Python has introduced the asyncio package to execute IO-bound tasks through concurrency concurrently. After several iterations, the asyncio APIs have worked very well, and the performance of concurrent tasks has improved dramatically compared to the multi-threaded version.
However, there are still many mistakes that programmers make when using asyncio:
One mistake, as shown in the figure below, is to use the await coroutine method directly in a way that changes the call to a concurrent task from asynchronous to synchronous, ultimately losing the concurrency feature.
async def main():
result_1 = await some_coro("name-1")
result_2 = await some_coro("name-2")Another mistake is shown in the figure below, although the programmer realizes that he needs to use create_task to create a task to be executed in the background. However, the following way of waiting for tasks one by one turns the tasks with different timings into an orderly wait.
async def main():
task_1 = asyncio.create_task(some_coro("name-1"))
task_2 = asyncio.create_task(some_coro("name-2"))
result_1 = await task_1
result_2 = await task_2This code will wait for task_1 to finish first, regardless of whether task_2 finishes first.
What is Concurrent Task Execution
So, what is a real concurrent task? Let’s use a diagram to illustrate:
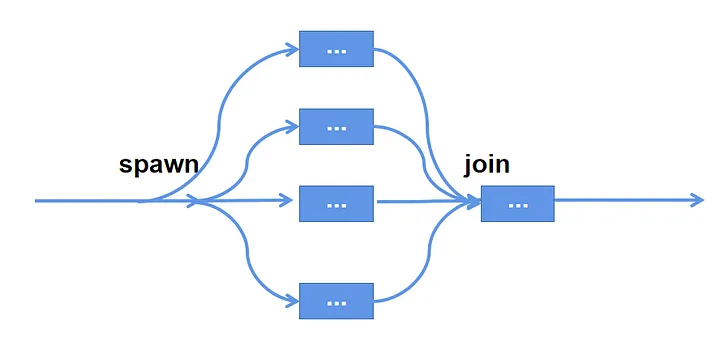
As the diagram shows, a concurrent process should consist of two parts: starting the background task, rejoining the background task back to the main function, and getting the result.
Most readers will already know how to use create_task to start a background task. Today, I will introduce a few ways to wait for a background task to complete and the best practices for each.
Getting Started
Before we start introducing today’s main character, we need to prepare a sample async method to simulate an IO-bound method call, as well as a custom AsyncException that can be used to kindly prompt an exception message when the test throws an exception:
from random import random, randint
import asyncio
class AsyncException(Exception):
def __init__(self, message, *args, **kwargs):
self.message = message
super(*args, **kwargs)
def __str__(self):
return self.message
async def some_coro(name):
print(f"Coroutine {name} begin to run")
value = random()
delay = randint(1, 4)
await asyncio.sleep(delay)
if value > 0.5:
raise AsyncException(f"Something bad happen after delay {delay} second(s)")
print(f"Coro {name} is Done. with delay {delay} second(s)")
return valueComparison of Methods For Concurrent Execution
Once we have done the preparations, it’s time to start the day’s journey and fasten your seat belt.
1. asyncio.gather
asyncio.gather can be used to start a set of background tasks, wait for them to finish executing, and get a list of results:
async def main():
aws, results = [], []
for i in range(3):
aws.append(asyncio.create_task(some_coro(f'name-{i}')))
results = await asyncio.gather(*aws) # need to unpack the list
for result in results:
print(f">got : {result}")
asyncio.run(main())asyncio.gather, although it forms a group of background tasks, cannot accept a list or collection as an argument directly. If you need to pass in a list containing background tasks, please unpack it.
asyncio.gather takes a return_exceptions argument. When the value of return_exception is False, if any background task throws an exception, it will be thrown to the caller of the gather method. And the result list of the gather method is empty.
async def main():
aws, results = [], []
for i in range(3):
aws.append(asyncio.create_task(some_coro(f'name-{i}')))
try:
results = await asyncio.gather(*aws, return_exceptions=False) # need to unpack the list
except AsyncException as e:
print(e)
for result in results:
print(f">got : {result}")
asyncio.run(main())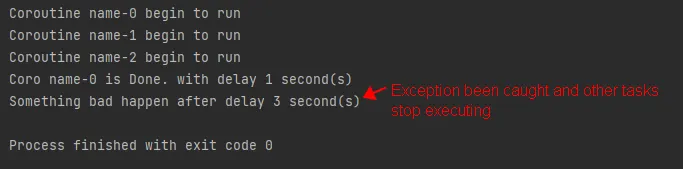
When the value of return_exception is True, exceptions thrown by background tasks will not affect the execution of other tasks and will eventually be merged into the result list and returned together.
results = await asyncio.gather(*aws, return_exceptions=True)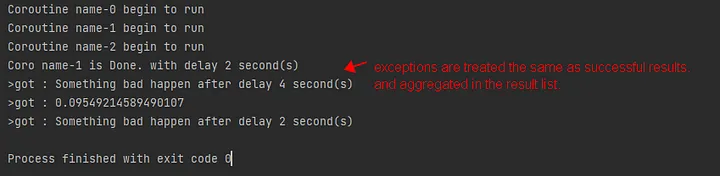
Next, let’s see why the gather method can’t accept a list directly, but has to unpack the list. Because when a list is filled and executed, it is difficult to add new tasks to the list while we wait for them to finish. However, the gather method can use nested groups to mix existing tasks with new ones, which solves the problem of not being able to add new tasks in the middle:
async def main():
aws, results = [], []
for i in range(3):
aws.append(asyncio.create_task(some_coro(f'name-{i}')))
group_1 = asyncio.gather(*aws) # note we don't use await now
# when some situation happen, we may add a new task
group_2 = asyncio.gather(group_1, asyncio.create_task(some_coro("a new task")))
results = await group_2
for result in results:
print(f">got : {result}")
asyncio.run(main())However, gather cannot set the timeout parameter directly. If you need to set a timeout for all running tasks, use this pose, which is not elegant enough.
async def main():
aws, results = [], []
for i in range(3):
aws.append(asyncio.create_task(some_coro(f'name-{i}')))
results = await asyncio.wait_for(asyncio.gather(*aws), timeout=2)
for result in results:
print(f">got : {result}")
asyncio.run(main())2. asyncio.as_completed
Sometimes, we must start the following action immediately after completing one background task. For example, when we crawl some data and immediately call the machine learning model for computation, the gather method cannot meet our needs, but we can use the as_completed method.
Before using asyncio.as_completed method, let’s look at this method’s source code.
# This is *not* a @coroutine! It is just an iterator (yielding Futures).
def as_completed(fs, *, timeout=None):
# ...
for f in todo:
f.add_done_callback(_on_completion)
if todo and timeout is not None:
timeout_handle = loop.call_later(timeout, _on_timeout)
for _ in range(len(todo)):
yield _wait_for_one()The source code shows that as_completed is not a concurrent method, and returns an iterator with a yield statement. So we can directly iterate over each completed background task, and we can handle exceptions for each task individually without affecting the execution of other tasks:
async def main():
aws = []
for i in range(5):
aws.append(asyncio.create_task(some_coro(f"name-{i}")))
for done in asyncio.as_completed(aws): # we don't need to unpack the list
try:
result = await done
print(f">got : {result}")
except AsyncException as e:
print(e)
asyncio.run(main())as_completed accepts the timeout argument, and the currently iterated task after the timeout occurs will throw asyncio.TimeoutError:
async def main():
aws = []
for i in range(5):
aws.append(asyncio.create_task(some_coro(f"name-{i}")))
for done in asyncio.as_completed(aws, timeout=2): # we don't need to unpack the list
try:
result = await done
print(f">got : {result}")
except AsyncException as e:
print(e)
except asyncio.TimeoutError: # we need to handle the TimeoutError
print("time out.")
asyncio.run(main())
as_completedis much more flexible than gather in terms of handling the results of task execution, but it is difficult to add new tasks to the original task list while waiting.
3. asyncio.wait
asyncio.wait is called in the same way as as_completed, but returns a tuple with two sets: done and pending. done holds the tasks that have finished executed, and pending holds the still-running tasks.
asyncio.wait accepts a return_when parameter, which can take three enumerated values:
- When
return_whenisasyncio.ALL_COMPLETED,donestores all completed tasks, andpendingis empty. - When
return_whenisasyncio.FIRST_COMPLETED,doneholds all completed tasks, andpendingholds the still-running tasks.
async def main():
aws = set()
for i in range(5):
aws.add(asyncio.create_task(some_coro(f"name-{i}")))
done, pending = await asyncio.wait(aws, return_when=asyncio.FIRST_COMPLETED)
for task in done:
try:
result = await task
print(f">got : {result}")
except AsyncException as e:
print(e)
print(f"the length of pending is {len(pending)}")
asyncio.run(main())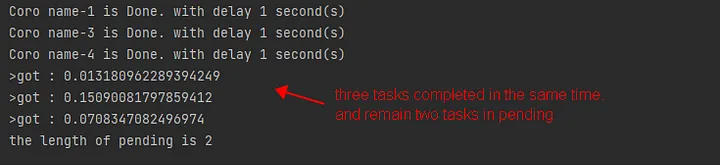
- When
return_whenisasyncio.FIRST_EXCEPTION,donestores the tasks that have thrown exceptions and completed execution, andpendingholds the still-running tasks.
When return_when is asyncio.FIRST_COMPLETED or asyncio.FIRST_EXECEPTION, we can call asyncio.wait recursively, so that we can add new tasks and keep waiting for all tasks to finish, depending on the situation.
async def main():
pending = set()
for i in range(5):
pending.add(asyncio.create_task(some_coro(f"name-{i}"))) # note the type and name of the task list
while pending:
done, pending = await asyncio.wait(pending, return_when=asyncio.FIRST_EXCEPTION)
for task in done:
try:
result = await task
print(f">got : {result}")
except AsyncException as e:
print(e)
pending.add(asyncio.create_task(some_coro("a new task")))
print(f"the length of pending is {len(pending)}")
asyncio.run(main())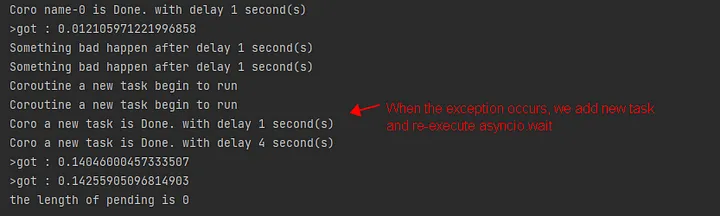
4. asyncio.TaskGroup
In Python 3.11, asyncio introduced the new TaskGroup API, which officially enables Python to support Structured Concurrency. This feature allows you to manage the life cycle of concurrent tasks in a more Pythonic way. For the sake of space, I won’t go into too much detail here, but interested readers can refer to my article:
 Peng Qian
Peng Qian
Conclusion
This article introduced the asyncio.gather, asyncio.as_completed, and asyncio.wait APIs, and also reviewed the new asyncio.TaskGroup feature introduced in Python 3.11.
Using these background task management methods according to actual needs can make our asyncio concurrent programming more flexible.
Due to experience, there are inevitably omissions in the exposition of this article, so please feel free to leave comments during the reading process, and I will reply actively.



